In the digitally vast world, an astounding 91.5% of the global population uses the internet to search for information.
Have you ever wondered how much data this equates to? This is where Python web scraping steps in, becoming a vital skill for data analysts, marketers, researchers, and many more. The demand for web scrapers has increased in the past few years along with the demand for Python Training in Ahmedabad!
Python web scraping is a technique used for extracting data from websites. Using various Python libraries, such as BeautifulSoup and Scrapy, you can pull out specific pieces of information from a webpage's HTML code, automate this process, and even store this data for future use.
So buckle up, and let's dive into the exciting world of Python web scraping!
A staggering 51% of global companies report using web scraping to gather data, demonstrating just how prevalent this method has become.
Libraries Used in Python Web Scraping
There are various Python libraries available for web scraping, each with its unique features and advantages:
- BeautifulSoup: A Python library used for parsing HTML and XML documents, perfect for beginners due to its simplicity.
- Scrapy: An open-source Python framework that handles large amounts of data and concurrent requests. It's more complex but extremely powerful.
- Selenium: This library is perfect for dealing with JavaScript-heavy websites as it can interact with web elements dynamically.
How to Scrape a Website Using Python?
Web scraping may seem daunting, especially if you're just starting. However, with Python, it can be simplified into a manageable process. Let's walk through a basic outline to get you started.
We'll be using the BeautifulSoup and Requests libraries, so you should ensure you have those installed first.
If not, you may use pip to install them:
pip install beautifulsoup4 requests
Please note that not all websites allow web scraping. Check a website's robots.txt file (add "/robots.txt" to the end of the URL) to see if they allow web scraping.
Even if a website allows it, you should not use web scraping to collect and use data in a way that violates terms of service or any relevant laws. Respect the website's policy and user's privacy.
Let's go step by step:
Prerequisites for Web Scraping
Before you start, you need to have Python installed on your machine. You can check if you have Python installed by running the command python3 -v in your terminal.
In addition to Python, you'll need to install the Python packages BeautifulSoup and Selenium, which can be done using pip:

Also, make sure to have Google Chrome and ChromeDriver installed on your machine. If we wish to utilise Selenium to scrape dynamically loaded material, we will need them.
Inspecting the Web Page
The first step in web scraping is to inspect the structure of the webpage you want to scrape. To do this, right-click the page and choose "Inspect Element".
This will open the browser's developer tools where you can see the HTML code structure of the page. Look for the HTML elements that contain the data you want to scrape. Each website is different, so you may need to adjust your scraping code accordingly.
Using BeautifulSoup to Extract Statically Loaded Content
BeautifulSoup is a Python library that makes it easy to scrape information from web pages.
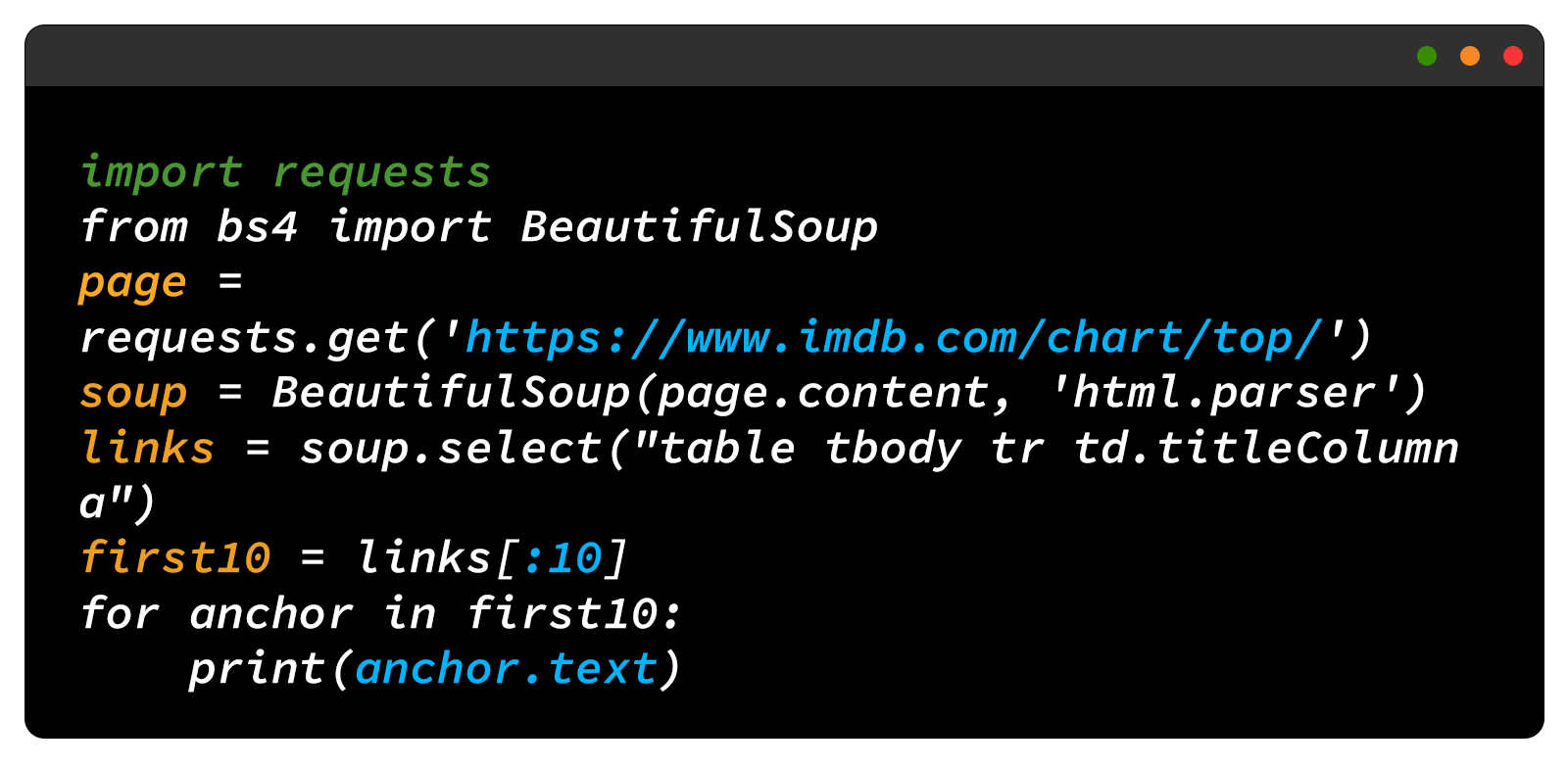
Here's an example of how to use BeautifulSoup to scrape the first ten movie titles from IMDb's top 250 movies list:
In this code, we are sending a request to the IMDb page, parsing the page's content with BeautifulSoup, selecting the HTML elements that contain the movie titles, and printing the titles.
Extracting Dynamically Loaded Content with Selenium
For pages that load content dynamically with JavaScript, you'll need to use a tool like Selenium which can simulate user interaction with a web page.
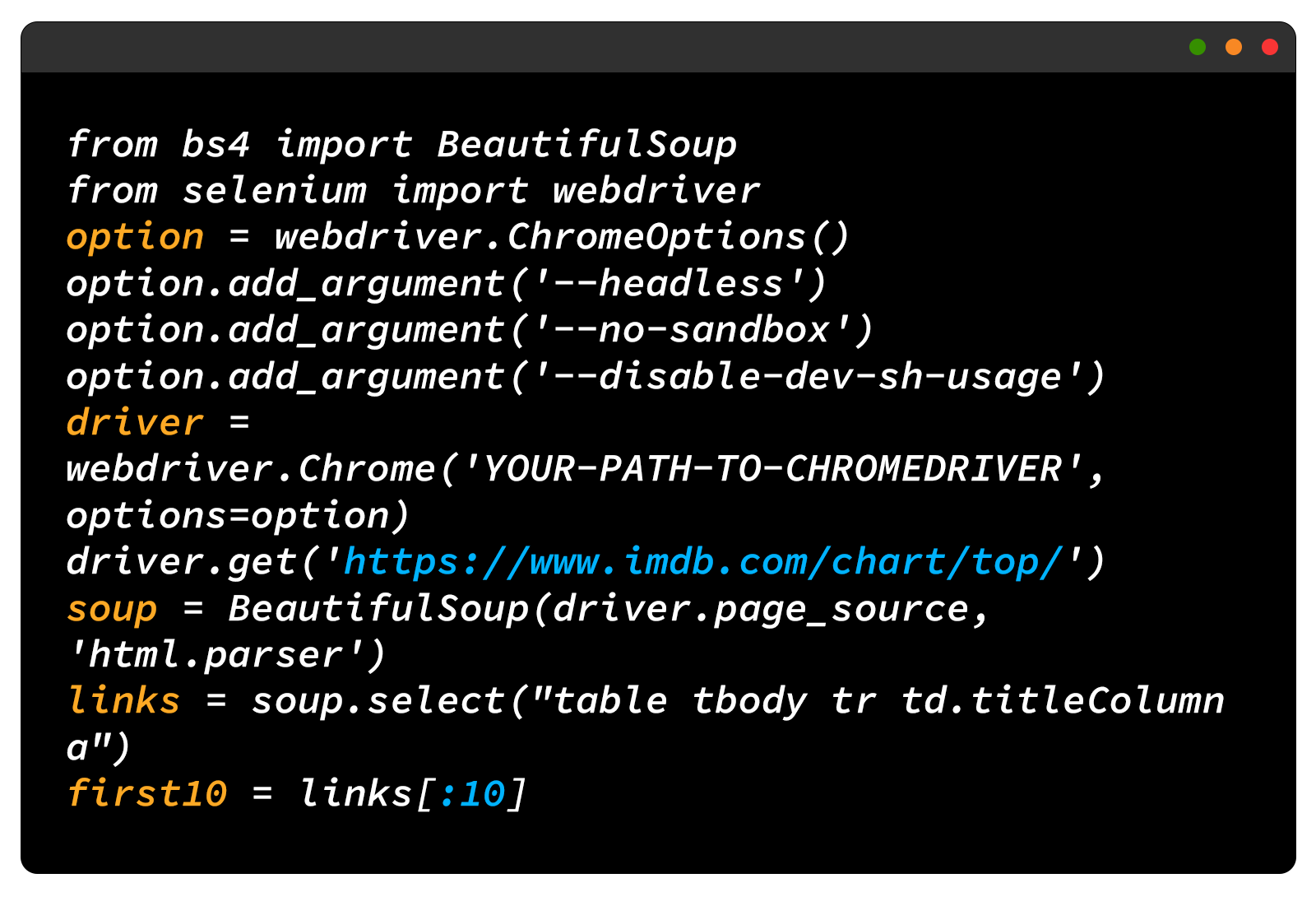
Here's an example of how to use Selenium to scrape the same IMDb page:
Here, instead of sending a simple HTTP request to get the page content, we are using Selenium to open the page in a browser, wait for the JavaScript to run, and then grab the HTML content of the page.
Don't forget to replace "YOUR-PATH-TO-CHROMEDRIVER" with the location where you extracted the chromedriver.
Note that when creating the BeautifulSoup object, driver.page_source is used instead of page.content, as it provides the HTML content of the page.
Saving the scraped data
Saving the scraped content can be accomplished in various ways depending on the data's nature and the format in which you want to save it. Two common formats are JSON and CSV, which are easily readable and manageable. Here is a simple example of how to do it in each format:
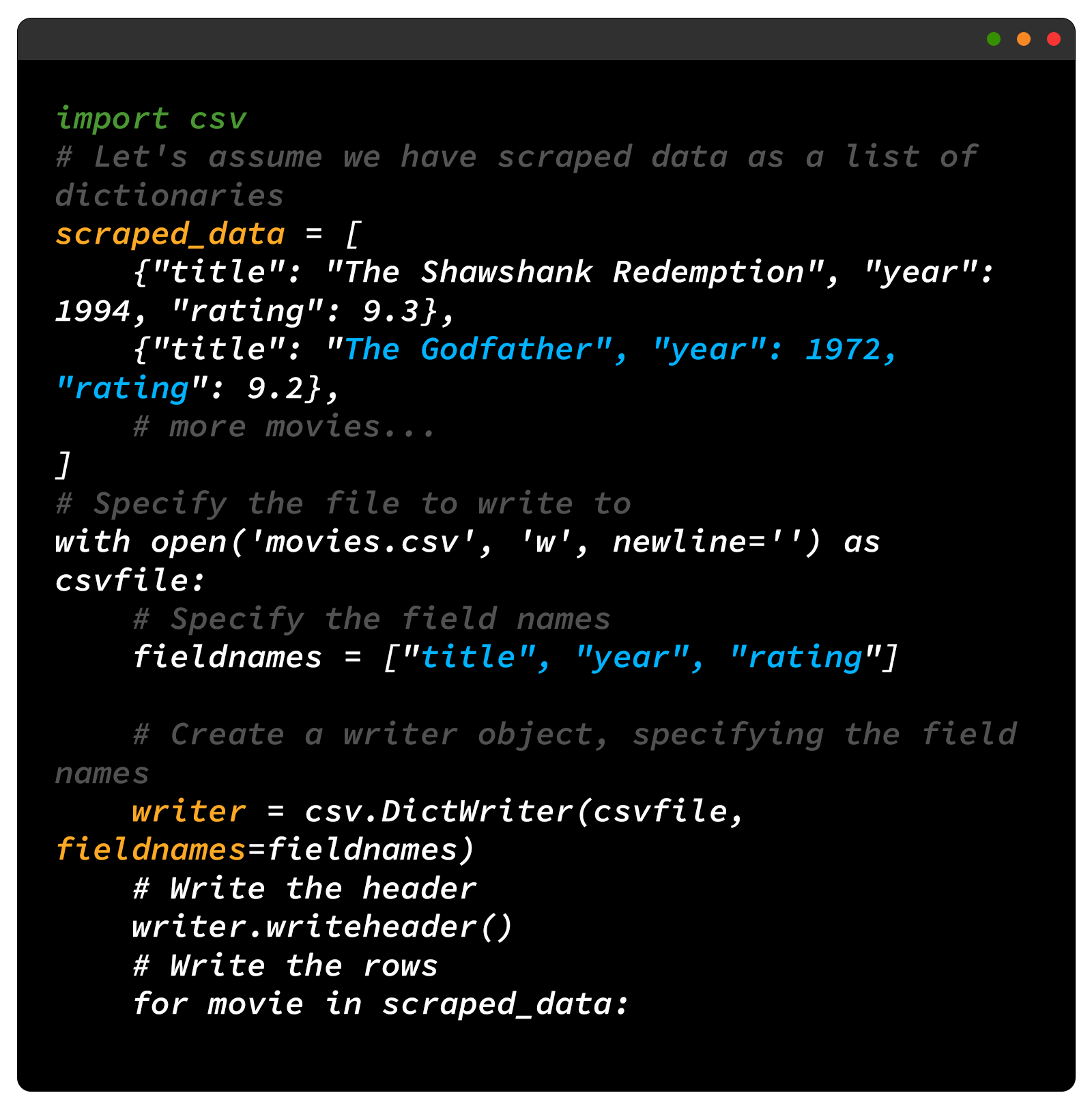
Saving as a CSV file: Python's built-in csv module makes it easy to write data into CSV files.
In both these examples, replace scraped_data with the actual data you've scraped. The keys in the dictionaries should correspond to the data you've gathered for each item.
Also Read: Top Python Interview Questions
Best Python Training In Ahmedabad
Python has emerged as one of the most in-demand programming languages in the digital era. Given its versatility, simplicity, and powerful features, Python is an excellent choice for beginners and experts. TOPS Technologies provides the best Python Training in Ahmedabad:
TOPS Technologies boasts a proud record of placing over 1 lakh students in reputable companies worldwide. We have a dedicated placement cell that provides intensive training and connects students with numerous job opportunities in the tech industry.
The quality of education provided at TOPS Technologies is superior, thanks to a team of expert teachers.
Completing the
Python Certification Course at TOPS Technologies earns students an NSDC Skill Certificate. This recognition is a testament to the skills and competence a student has garnered during the course. This credential helps differentiate students in the competitive job market, demonstrating their mastery of Python.
Conclusion
Web scraping with Python is a highly sought-after data extraction and automation skill. Understanding and implementing this concept correctly could be a game-changer in any tech-related career.
By enrolling in the Python course at TOPS Technologies, you gain a comprehensive understanding of Python and its various applications, including web scraping. You learn from industry professionals, gain a prestigious certification, and get a foot in the door of the thriving tech industry with their exceptional placement record. With our
Python Training in Surat, you're not just learning Python; you're setting the foundation for a prosperous career in technology.